Chapter 16: Resource Aware Optimization
Chapter 16: Resource-Aware Optimization | 第 16 章:资源感知优化
Resource-Aware Optimization enables intelligent agents to dynamically monitor and manage computational, temporal, and financial resources during operation. This differs from simple planning, which primarily focuses on action sequencing. Resource-Aware Optimization requires agents to make decisions regarding action execution to achieve goals within specified resource budgets or to optimize efficiency. This involves choosing between more accurate but expensive models and faster, lower-cost ones, or deciding whether to allocate additional compute for a more refined response versus returning a quicker, less detailed answer.
资源感知优化使具智能体特性的系统能够在运行过程中动态监控和管理计算、时间和财务资源。这与简单的规划不同,后者主要关注动作序列。资源感知优化要求智能体在执行动作时做出决策,以在指定的资源预算内实现目标或优化效率。这涉及在更准确但昂贵的模型与更快速但成本较低的模型之间进行选择,或者决定是否为更精细的响应分配额外的计算资源,还是返回更快速但不太详细的答案。
For example, consider an agent tasked with analyzing a large dataset for a financial analyst. If the analyst needs a preliminary report immediately, the agent might use a faster, more affordable model to quickly summarize key trends. However, if the analyst requires a highly accurate forecast for a critical investment decision and has a larger budget and more time, the agent would allocate more resources to utilize a powerful, slower, but more precise predictive model. A key strategy in this category is the fallback mechanism, which acts as a safeguard when a preferred model is unavailable due to being overloaded or throttled. To ensure graceful degradation, the system automatically switches to a default or more affordable model, maintaining service continuity instead of failing completely.
例如,考虑一个负责为金融分析师分析大型数据集的智能体。如果分析师需要立即获得初步报告,智能体可能会使用更快速、更实惠的模型来快速总结关键趋势。然而,如果分析师需要为关键投资决策提供高度准确的预测,并且有更大的预算和更多时间,智能体将分配更多资源来使用强大、较慢但更精确的预测模型。此类别中的一个关键策略是后备机制,当首选模型由于过载或限流而不可用时,它充当保护措施。为确保优雅降级,系统会自动切换到默认或更实惠的模型,从而维持服务连续性,而不是完全失败。
Practical Applications & Use Cases | 实际应用与用例
Practical use cases include:
实际用例包括:
- Cost-Optimized LLM Usage: An agent deciding whether to use a large, expensive LLM for complex tasks or a smaller, more affordable one for simpler queries, based on a budget constraint.
* 成本优化的 LLM 使用:智能体根据预算约束,决定是使用大型、昂贵的 LLM 处理复杂任务,还是使用较小、更实惠的 LLM 处理简单查询。
- Latency-Sensitive Operations: In real-time systems, an agent chooses a faster but potentially less comprehensive reasoning path to ensure a timely response.
* 延迟敏感操作:在实时系统中,智能体选择更快但可能不太全面的推理路径,以确保及时响应。
- Energy Efficiency: For agents deployed on edge devices or with limited power, optimizing their processing to conserve battery life.
* 能源效率:对于部署在边缘设备或电力有限的智能体,优化其处理以节省电池寿命。
- Fallback for service reliability: An agent automatically switches to a backup model when the primary choice is unavailable, ensuring service continuity and graceful degradation.
* 服务可靠性的后备机制:当主要选择不可用时,智能体自动切换到备份模型,确保服务连续性和优雅降级。
- Data Usage Management: An agent opting for summarized data retrieval instead of full dataset downloads to save bandwidth or storage.
* 数据使用管理:智能体选择摘要数据检索而不是完整数据集下载,以节省带宽或存储空间。
- Adaptive Task Allocation: In multi-agent systems, agents self-assign tasks based on their current computational load or available time.
* 自适应任务分配:在多智能体系统中,智能体根据当前计算负载或可用时间自行分配任务。
Hands-On Code Example | 实战代码示例
An intelligent system for answering user questions can assess the difficulty of each question. For simple queries, it utilizes a cost-effective language model such as Gemini Flash. For complex inquiries, a more powerful, but expensive, language model (like Gemini Pro) is considered. The decision to use the more powerful model also depends on resource availability, specifically budget and time constraints. This system dynamically selects appropriate models.
一个用于回答用户问题的智能系统可以评估每个问题的难度。对于简单查询,它使用成本效益高的语言模型,如 Gemini Flash。对于复杂查询,会考虑使用更强大但昂贵的语言模型(如 Gemini Pro)。使用更强大模型的决定还取决于资源可用性,特别是预算和时间约束。该系统会动态选择适当的模型。
For example, consider a travel planner built with a hierarchical agent. The high-level planning, which involves understanding a user's complex request, breaking it down into a multi-step itinerary, and making logical decisions, would be managed by a sophisticated and more powerful LLM like Gemini Pro. This is the "planner" agent that requires a deep understanding of context and the ability to reason.
例如,考虑使用层次化智能体构建的旅行规划器。高层规划涉及理解用户的复杂请求、将其分解为多步骤行程并做出逻辑决策,这将由复杂且更强大的 LLM(如 Gemini Pro)管理。这是需要深入理解上下文和推理能力的「规划器」智能体。
However, once the plan is established, the individual tasks within that plan, such as looking up flight prices, checking hotel availability, or finding restaurant reviews, are essentially simple, repetitive web queries. These "tool function calls" can be executed by a faster and more affordable model like Gemini Flash. It is easier to visualize why the affordable model can be used for these straightforward web searches, while the intricate planning phase requires the greater intelligence of the more advanced model to ensure a coherent and logical travel plan.
然而,一旦确定了计划,该计划中的各个任务(如查找航班价格、检查酒店可用性或查找餐厅评论)本质上是简单、重复的网络查询。这些「工具函数调用」可以由更快速、更实惠的模型(如 Gemini Flash)执行。很容易理解为什么这些直接的网络搜索可以使用实惠的模型,而复杂的规划阶段需要更先进模型的更强智能,以确保连贯且合乎逻辑的旅行计划。
Google's ADK supports this approach through its multi-agent architecture, which allows for modular and scalable applications. Different agents can handle specialized tasks. Model flexibility enables the direct use of various Gemini models, including both Gemini Pro and Gemini Flash, or integration of other models through LiteLLM. The ADK's orchestration capabilities support dynamic, LLM-driven routing for adaptive behavior. Built-in evaluation features allow systematic assessment of agent performance, which can be used for system refinement (see the Chapter on Evaluation and Monitoring).
Google 的 ADK 通过其多智能体架构支持这种方法,允许模块化和可扩展的应用程序。不同的智能体可以处理专门的任务。模型灵活性支持直接使用各种 Gemini 模型,包括 Gemini Pro 和 Gemini Flash,或通过 LiteLLM 集成其他模型。ADK 的编排功能支持动态的、由 LLM 驱动的路由,以实现自适应行为。内置的评估功能允许系统化评估智能体性能,可用于系统优化(参见评估与监控章节)。
Next, two agents with identical setup but utilizing different models and costs will be defined.
接下来,将定义两个设置相同但使用不同模型和成本的智能体。
# Conceptual Python-like structure, not runnable code
from google.adk.agents import Agent
# from google.adk.models.lite_llm import LiteLlm # If using models not directly supported by ADK's default Agent
# Agent using the more expensive Gemini Pro 2.5
gemini_pro_agent = Agent(
name="GeminiProAgent",
model="gemini-2.5-pro", # Placeholder for actual model name if different
description="A highly capable agent for complex queries.",
instruction="You are an expert assistant for complex problem-solving."
)
# Agent using the less expensive Gemini Flash 2.5
gemini_flash_agent = Agent(
name="GeminiFlashAgent",
model="gemini-2.5-flash", # Placeholder for actual model name if different
description="A fast and efficient agent for simple queries.",
instruction="You are a quick assistant for straightforward questions."
)
上述代码定义了两个智能体:GeminiProAgent 使用更昂贵的 Gemini Pro 2.5 模型处理复杂查询,而 GeminiFlashAgent 使用更实惠的 Gemini Flash 2.5 模型处理简单查询。
Router Agent | 路由智能体
A Router Agent can direct queries based on simple metrics like query length, where shorter queries go to less expensive models and longer queries to more capable models. However, a more sophisticated Router Agent can utilize either LLM or ML models to analyze query nuances and complexity. This LLM router can determine which downstream language model is most suitable. For example, a query requesting a factual recall is routed to a flash model, while a complex query requiring deep analysis is routed to a pro model.
路由智能体可以基于简单的指标(如查询长度)来引导查询,其中较短的查询发送到成本较低的模型,较长的查询发送到更强大的模型。然而,更复杂的路由智能体可以利用 LLM 或 ML 模型来分析查询的细微差别和复杂性。这个 LLM 路由器可以确定哪个下游语言模型最合适。例如,请求事实回忆的查询被路由到 Flash 模型,而需要深入分析的复杂查询被路由到 Pro 模型。
Optimization techniques can further enhance the LLM router's effectiveness. Prompt tuning involves crafting prompts to guide the router LLM for better routing decisions. Fine-tuning the LLM router on a dataset of queries and their optimal model choices improves its accuracy and efficiency. This dynamic routing capability balances response quality with cost-effectiveness.
优化技术可以进一步提高 LLM 路由器的有效性。提示调优涉及精心设计提示以指导路由器 LLM 做出更好的路由决策。在查询及其最优模型选择的数据集上对 LLM 路由器进行微调,可以提高其准确性和效率。这种动态路由能力在响应质量和成本效益之间取得平衡。
# Conceptual Python-like structure, not runnable code
from google.adk.agents import Agent, BaseAgent
from google.adk.events import Event
from google.adk.agents.invocation_context import InvocationContext
import asyncio
class QueryRouterAgent(BaseAgent):
name: str = "QueryRouter"
description: str = "Routes user queries to the appropriate LLM agent based on complexity."
async def _run_async_impl(self, context: InvocationContext) -> AsyncGenerator[Event, None]:
user_query = context.current_message.text # Assuming text input
query_length = len(user_query.split()) # Simple metric: number of words
if query_length < 20: # Example threshold for simplicity vs. complexity
print(f"Routing to Gemini Flash Agent for short query (length: {query_length})")
# In a real ADK setup, you would 'transfer_to_agent' or directly invoke
# For demonstration, we'll simulate a call and yield its response
response = await gemini_flash_agent.run_async(context.current_message)
yield Event(author=self.name, content=f"Flash Agent processed: {response}")
else:
print(f"Routing to Gemini Pro Agent for long query (length: {query_length})")
response = await gemini_pro_agent.run_async(context.current_message)
yield Event(author=self.name, content=f"Pro Agent processed: {response}")
上述代码实现了 QueryRouterAgent 类,它根据查询的复杂度将用户查询路由到适当的 LLM 智能体。它使用简单的指标(查询中的单词数)来确定复杂度。短查询(少于 20 个单词)被路由到 Gemini Flash Agent,而长查询被路由到 Gemini Pro Agent。
Critique Agent | 评论智能体
The Critique Agent evaluates responses from language models, providing feedback that serves several functions. For self-correction, it identifies errors or inconsistencies, prompting the answering agent to refine its output for improved quality. It also systematically assesses responses for performance monitoring, tracking metrics like accuracy and relevance, which are used for optimization.
评论智能体评估来自语言模型的响应,提供服务于多种功能的反馈。对于自我修正,它识别错误或不一致之处,促使回答智能体改进其输出以提高质量。它还系统化地评估响应以进行性能监控,跟踪准确性和相关性等指标,这些指标用于优化。
Additionally, its feedback can signal reinforcement learning or fine-tuning; consistent identification of inadequate Flash model responses, for instance, can refine the router agent's logic. While not directly managing the budget, the Critique Agent contributes to indirect budget management by identifying suboptimal routing choices, such as directing simple queries to a Pro model or complex queries to a Flash model, which leads to poor results. This informs adjustments that improve resource allocation and cost savings.
此外,其反馈可以为强化学习或微调提供信号;例如,持续识别 Flash 模型的不充分响应可以改进路由智能体的逻辑。虽然不直接管理预算,但评论智能体通过识别次优路由选择(如将简单查询引导到 Pro 模型或将复杂查询引导到 Flash 模型,从而导致不良结果)来促进间接预算管理。这为改进资源分配和成本节约的调整提供了信息。
The Critique Agent can be configured to review either only the generated text from the answering agent or both the original query and the generated text, enabling a comprehensive evaluation of the response's alignment with the initial question.
评论智能体可以配置为仅审查来自回答智能体的生成文本,或同时审查原始查询和生成文本,从而能够全面评估响应与初始问题的对齐情况。
CRITIC_SYSTEM_PROMPT = """
You are the **Critic Agent**, serving as the quality assurance arm of our collaborative research assistant system. Your primary function is to **meticulously review and challenge** information from the Researcher Agent, guaranteeing **accuracy, completeness, and unbiased presentation**.
Your duties encompass:
* **Assessing research findings** for factual correctness, thoroughness, and potential leanings.
* **Identifying any missing data** or inconsistencies in reasoning.
* **Raising critical questions** that could refine or expand the current understanding.
* **Offering constructive suggestions** for enhancement or exploring different angles.
* **Validating that the final output is comprehensive** and balanced.
All criticism must be constructive. Your goal is to fortify the research, not invalidate it. Structure your feedback clearly, drawing attention to specific points for revision. Your overarching aim is to ensure the final research product meets the highest possible quality standards.
"""
上述代码展示了评论智能体的系统提示模板 CRITIC_SYSTEM_PROMPT。该提示明确定义了智能体作为质量保证组件的角色,职责包括评估研究结果的准确性、识别缺失数据、提出批判性问题、提供建设性建议,并验证最终输出的全面性和平衡性。
The Critic Agent operates based on a predefined system prompt that outlines its role, responsibilities, and feedback approach. A well-designed prompt for this agent must clearly establish its function as an evaluator. It should specify the areas for critical focus and emphasize providing constructive feedback rather than mere dismissal. The prompt should also encourage the identification of both strengths and weaknesses, and it must guide the agent on how to structure and present its feedback.
评论智能体基于预定义的系统提示运行,该提示概述了其角色、职责和反馈方法。为该智能体设计良好的提示必须清楚地确立其作为评估者的功能。它应该指定需要重点关注的领域,并强调提供建设性反馈而不是简单地否定。提示还应鼓励识别优势和劣势,并且必须指导智能体如何构建和呈现其反馈。
Hands-On Code with OpenAI | 使用 OpenAI 的实战代码
This system uses a resource-aware optimization strategy to handle user queries efficiently. It first classifies each query into one of three categories to determine the most appropriate and cost-effective processing pathway. This approach avoids wasting computational resources on simple requests while ensuring complex queries get the necessary attention. The three categories are:
该系统使用资源感知优化策略来高效处理用户查询。它首先将每个查询分类为三个类别之一,以确定最合适且最具成本效益的处理路径。这种方法避免了在简单请求上浪费计算资源,同时确保复杂查询获得必要的关注。三个类别是:
- simple: For straightforward questions that can be answered directly without complex reasoning or external data.
* simple(简单):用于可以直接回答而无需复杂推理或外部数据的直接问题。
- reasoning: For queries that require logical deduction or multi-step thought processes, which are routed to more powerful models.
* reasoning(推理):用于需要逻辑推理或多步骤思考过程的查询,这些查询被路由到更强大的模型。
- internet_search: For questions needing current information, which automatically triggers a Google Search to provide an up-to-date answer.
* internet_search(网络搜索):用于需要当前信息的问题,会自动触发 Google 搜索以提供最新答案。
The code is under the MIT license and available on Github: (https://github.com/mahtabsyed/21-Agentic-Patterns/blob/main/16_Resource_Aware_Opt_LLM_Reflection_v2.ipynb)
该代码采用 MIT 许可证,可在 GitHub 上获取:(https://github.com/mahtabsyed/21-Agentic-Patterns/blob/main/16_Resource_Aware_Opt_LLM_Reflection_v2.ipynb)
# MIT License
# Copyright (c) 2025 Mahtab Syed
# https://www.linkedin.com/in/mahtabsyed/
import os
import requests
import json
from dotenv import load_dotenv
from openai import OpenAI
# Load environment variables
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
GOOGLE_CUSTOM_SEARCH_API_KEY = os.getenv("GOOGLE_CUSTOM_SEARCH_API_KEY")
GOOGLE_CSE_ID = os.getenv("GOOGLE_CSE_ID")
if not OPENAI_API_KEY or not GOOGLE_CUSTOM_SEARCH_API_KEY or not GOOGLE_CSE_ID:
raise ValueError(
"Please set OPENAI_API_KEY, GOOGLE_CUSTOM_SEARCH_API_KEY, and GOOGLE_CSE_ID in your .env file."
)
client = OpenAI(api_key=OPENAI_API_KEY)
# --- Step 1: Classify the Prompt ---
def classify_prompt(prompt: str) -> dict:
system_message = {
"role": "system",
"content": (
"You are a classifier that analyzes user prompts and returns one of three categories ONLY:\n\n"
"- simple\n"
"- reasoning\n"
"- internet_search\n\n"
"Rules:\n"
"- Use 'simple' for direct factual questions that need no reasoning or current events.\n"
"- Use 'reasoning' for logic, math, or multi-step inference questions.\n"
"- Use 'internet_search' if the prompt refers to current events, recent data, or things not in your training data.\n\n"
"Respond ONLY with JSON like:\n"
'{ "classification": "simple" }'
),
}
user_message = {"role": "user", "content": prompt}
response = client.chat.completions.create(
model="gpt-4o", messages=[system_message, user_message], temperature=1
)
reply = response.choices[0].message.content
return json.loads(reply)
# --- Step 2: Google Search ---
def google_search(query: str, num_results=1) -> list:
url = "https://www.googleapis.com/customsearch/v1"
params = {
"key": GOOGLE_CUSTOM_SEARCH_API_KEY,
"cx": GOOGLE_CSE_ID,
"q": query,
"num": num_results,
}
try:
response = requests.get(url, params=params)
response.raise_for_status()
results = response.json()
if "items" in results and results["items"]:
return [
{
"title": item.get("title"),
"snippet": item.get("snippet"),
"link": item.get("link"),
}
for item in results["items"]
]
else:
return []
except requests.exceptions.RequestException as e:
return {"error": str(e)}
# --- Step 3: Generate Response ---
def generate_response(prompt: str, classification: str, search_results=None) -> str:
if classification == "simple":
model = "gpt-4o-mini"
full_prompt = prompt
elif classification == "reasoning":
model = "o4-mini"
full_prompt = prompt
elif classification == "internet_search":
model = "gpt-4o"
# Convert each search result dict to a readable string
if search_results:
search_context = "\n".join(
[
f"Title: {item.get('title')}\nSnippet: {item.get('snippet')}\nLink: {item.get('link')}"
for item in search_results
]
)
else:
search_context = "No search results found."
full_prompt = f"""Use the following web results to answer the user query:
{search_context}
Query: {prompt}"""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": full_prompt}],
temperature=1,
)
return response.choices[0].message.content, model
# --- Step 4: Combined Router ---
def handle_prompt(prompt: str) -> dict:
classification_result = classify_prompt(prompt)
classification = classification_result["classification"]
search_results = None
if classification == "internet_search":
search_results = google_search(prompt)
answer, model = generate_response(prompt, classification, search_results)
return {"classification": classification, "response": answer, "model": model}
test_prompt = "What is the capital of Australia?"
# test_prompt = "Explain the impact of quantum computing on cryptography."
# test_prompt = "When does the Australian Open 2026 start, give me full date?"
result = handle_prompt(test_prompt)
print("🔍 Classification:", result["classification"])
print("🧠 Model Used:", result["model"])
print("🧠 Response:\n", result["response"])
该 Python 代码实现了一个提示路由系统来回答用户问题。它首先从 .env 文件加载 OpenAI 和 Google Custom Search 所需的 API 密钥。核心功能在于将用户的提示分类为三个类别:simple(简单)、reasoning(推理)或 internet_search(网络搜索)。专门的函数 classify_prompt 利用 OpenAI 模型执行此分类步骤。如果提示需要当前信息,则使用 Google Custom Search API 执行 Google 搜索。另一个函数 generate_response 根据分类选择适当的 OpenAI 模型生成最终响应。对于网络搜索查询,搜索结果作为上下文提供给模型。主函数 handle_prompt 协调此工作流程,在生成响应之前调用分类和搜索(如果需要)函数。它返回分类、使用的模型和生成的答案。该系统有效地将不同类型的查询引导到优化的方法以获得更好的响应。
Hands-On Code Example (OpenRouter) | 使用 OpenRouter 的实战代码
OpenRouter offers a unified interface to hundreds of AI models via a single API endpoint. It provides automated failover and cost-optimization, with easy integration through your preferred SDK or framework.
OpenRouter 通过单个 API 端点提供对数百个 AI 模型的统一接口。它提供自动故障转移和成本优化,可通过您喜欢的 SDK 或框架轻松集成。
import requests
import json
response = requests.post(
url="https://openrouter.ai/api/v1/chat/completions",
headers={
"Authorization": "Bearer <OPENROUTER_API_KEY>",
"HTTP-Referer": "<YOUR_SITE_URL>", # Optional. Site URL for rankings on openrouter.ai.
"X-Title": "<YOUR_SITE_NAME>", # Optional. Site title for rankings on openrouter.ai.
},
data=json.dumps({
"model": "openai/gpt-4o", # Optional
"messages": [
{
"role": "user",
"content": "What is the meaning of life?"
}
]
})
)
此代码片段使用 requests 库与 OpenRouter API 交互。它向聊天完成端点发送 POST 请求,包含用户消息。请求包括带有 API 密钥的授权标头和可选的站点信息。目标是从指定的语言模型(在本例中为 openai/gpt-4o)获取响应。
Openrouter offers two distinct methodologies for routing and determining the computational model used to process a given request.
OpenRouter 提供两种不同的方法来路由和确定用于处理给定请求的计算模型。
- Automated Model Selection: This function routes a request to an optimized model chosen from a curated set of available models. The selection is predicated on the specific content of the user's prompt. The identifier of the model that ultimately processes the request is returned in the response's metadata.
* 自动模型选择:此功能将请求路由到从精选的可用模型集中选择的优化模型。选择基于用户提示的具体内容。最终处理请求的模型标识符在响应的元数据中返回。
{
"model": "openrouter/auto",
... // Other params
}
- Sequential Model Fallback: This mechanism provides operational redundancy by allowing users to specify a hierarchical list of models. The system will first attempt to process the request with the primary model designated in the sequence. Should this primary model fail to respond due to any number of error conditions—such as service unavailability, rate-limiting, or content filtering—the system will automatically re-route the request to the next specified model in the sequence. This process continues until a model in the list successfully executes the request or the list is exhausted. The final cost of the operation and the model identifier returned in the response will correspond to the model that successfully completed the computation.
* 顺序模型回退:此机制通过允许用户指定分层模型列表来提供操作冗余。系统将首先尝试使用序列中指定的主要模型处理请求。如果主要模型由于多种错误条件(如服务不可用、速率限制或内容过滤)而无法响应,系统将自动将请求重新路由到序列中的下一个指定模型。此过程将持续进行,直到列表中的某个模型成功执行请求或列表耗尽。操作的最终成本和响应中返回的模型标识符将对应于成功完成计算的模型。
{
"models": ["anthropic/claude-3.5-sonnet", "gryphe/mythomax-l2-13b"],
... // Other params
}
OpenRouter offers a detailed leaderboard (https://openrouter.ai/rankings) which ranks available AI models based on their cumulative token production. It also offers latest models from different providers (ChatGPT, Gemini, Claude) (see Fig. 1)
OpenRouter 提供详细的排行榜(https://openrouter.ai/rankings),根据累积令牌生产量对可用的 AI 模型进行排名。它还提供来自不同提供商(ChatGPT、Gemini、Claude)的最新模型(见图 1)。
图 1:OpenRouter 网站 (https://openrouter.ai/)
Beyond Dynamic Model Switching: A Spectrum of Agent Resource Optimizations | 超越动态模型切换:智能体资源优化的全景
Resource-aware optimization is paramount in developing intelligent agent systems that operate efficiently and effectively within real-world constraints. Let's see a number of additional techniques:
资源感知优化在开发能够在现实世界约束下高效且有效运行的具智能体特性的系统中至关重要。让我们看看许多其他技术:
Dynamic Model Switching is a critical technique involving the strategic selection of large language models based on the intricacies of the task at hand and the available computational resources. When faced with simple queries, a lightweight, cost-effective LLM can be deployed, whereas complex, multifaceted problems necessitate the utilization of more sophisticated and resource-intensive models.
动态模型切换是一种关键技术,涉及基于手头任务的复杂性和可用计算资源对大型语言模型的战略选择。面对简单查询时,可以部署轻量级、成本效益高的 LLM,而复杂的多方面问题则需要使用更复杂和资源密集的模型。
Adaptive Tool Use & Selection ensures agents can intelligently choose from a suite of tools, selecting the most appropriate and efficient one for each specific sub-task, with careful consideration given to factors like API usage costs, latency, and execution time. This dynamic tool selection enhances overall system efficiency by optimizing the use of external APIs and services.
自适应工具使用与选择确保智能体能够从一组工具中智能选择,为每个特定子任务选择最合适和最高效的工具,并仔细考虑 API 使用成本、延迟和执行时间等因素。这种动态工具选择通过优化外部 API 和服务的使用来提高整体系统效率。
Contextual Pruning & Summarization plays a vital role in managing the amount of information processed by agents, strategically minimizing the prompt token count and reducing inference costs by intelligently summarizing and selectively retaining only the most relevant information from the interaction history, preventing unnecessary computational overhead.
上下文修剪与摘要在管理智能体处理的信息量方面发挥着至关重要的作用,通过智能摘要和选择性地仅保留交互历史中最相关的信息来战略性地最小化提示令牌数并降低推理成本,从而防止不必要的计算开销。
Proactive Resource Prediction involves anticipating resource demands by forecasting future workloads and system requirements, which allows for proactive allocation and management of resources, ensuring system responsiveness and preventing bottlenecks.
主动资源预测涉及通过预测未来工作负载和系统需求来预测资源需求,从而允许主动分配和管理资源,确保系统响应性并防止瓶颈。
Cost-Sensitive Exploration in multi-agent systems extends optimization considerations to encompass communication costs alongside traditional computational costs, influencing the strategies employed by agents to collaborate and share information, aiming to minimize the overall resource expenditure.
成本敏感探索在多智能体系统中将优化考虑扩展到包括通信成本以及传统计算成本,影响智能体协作和共享信息所采用的策略,旨在最小化整体资源支出。
Energy-Efficient Deployment is specifically tailored for environments with stringent resource constraints, aiming to minimize the energy footprint of intelligent agent systems, extending operational time and reducing overall running costs.
能源高效部署专门针对具有严格资源约束的环境而定制,旨在最小化具智能体特性系统的能源足迹,延长运行时间并降低整体运行成本。
Parallelization & Distributed Computing Awareness leverages distributed resources to enhance the processing power and throughput of agents, distributing computational workloads across multiple machines or processors to achieve greater efficiency and faster task completion.
并行化与分布式计算感知利用分布式资源来增强智能体的处理能力和吞吐量,将计算工作负载分布到多台机器或处理器上,以实现更高的效率和更快的任务完成。
Learned Resource Allocation Policies introduce a learning mechanism, enabling agents to adapt and optimize their resource allocation strategies over time based on feedback and performance metrics, improving efficiency through continuous refinement.
学习型资源分配策略引入学习机制,使智能体能够基于反馈和性能指标随时间推移适应和优化其资源分配策略,通过持续改进提高效率。
Graceful Degradation and Fallback Mechanisms ensure that intelligent agent systems can continue to function, albeit perhaps at a reduced capacity, even when resource constraints are severe, gracefully degrading performance and falling back to alternative strategies to maintain operation and provide essential functionality.
优雅降级和后备机制确保具智能体特性的系统即使在资源约束严重时也能继续运行(尽管可能以降低的容量),优雅地降低性能并回退到替代策略以维持运行并提供基本功能。
At a Glance | 要点速览
What: Resource-Aware Optimization addresses the challenge of managing the consumption of computational, temporal, and financial resources in intelligent systems. LLM-based applications can be expensive and slow, and selecting the best model or tool for every task is often inefficient. This creates a fundamental trade-off between the quality of a system's output and the resources required to produce it. Without a dynamic management strategy, systems cannot adapt to varying task complexities or operate within budgetary and performance constraints.
问题所在:资源感知优化解决了在具智能体特性的系统中管理计算、时间和财务资源消耗的挑战。基于 LLM 的应用程序可能既昂贵又缓慢,为每个任务选择最佳模型或工具往往效率低下。这在系统输出质量与生成所需资源之间产生了根本性权衡。如果没有动态管理策略,系统无法适应不同的任务复杂性或在预算和性能约束内运行。
Why: The standardized solution is to build an agentic system that intelligently monitors and allocates resources based on the task at hand. This pattern typically employs a "Router Agent" to first classify the complexity of an incoming request. The request is then forwarded to the most suitable LLM or tool—a fast, inexpensive model for simple queries, and a more powerful one for complex reasoning. A "Critique Agent" can further refine the process by evaluating the quality of the response, providing feedback to improve the routing logic over time. This dynamic, multi-agent approach ensures the system operates efficiently, balancing response quality with cost-effectiveness.
解决之道:标准化解决方案是构建一个具智能体特性的系统,根据手头的任务智能地监控和分配资源。此模式通常使用「路由智能体」首先对传入请求的复杂性进行分类。然后将请求转发到最合适的 LLM 或工具——简单查询使用快速、廉价的模型,复杂推理使用更强大的模型。「评论智能体」可以通过评估响应质量进一步改进流程,提供反馈以随时间改进路由逻辑。这种动态的多智能体方法确保系统高效运行,在响应质量和成本效益之间取得平衡。
Rule of thumb: Use this pattern when operating under strict financial budgets for API calls or computational power, building latency-sensitive applications where quick response times are critical, deploying agents on resource-constrained hardware such as edge devices with limited battery life, programmatically balancing the trade-off between response quality and operational cost, and managing complex, multi-step workflows where different tasks have varying resource requirements.
经验法则:在以下情况下使用此模式:在 API 调用或计算能力的严格财务预算下运行;构建对延迟敏感的应用程序,其中快速响应时间至关重要;在资源受限的硬件(如电池寿命有限的边缘设备)上部署智能体;以编程方式平衡响应质量和运营成本之间的权衡;以及管理复杂的多步骤工作流程,其中不同任务具有不同的资源需求。
Visual Summary | 可视化摘要
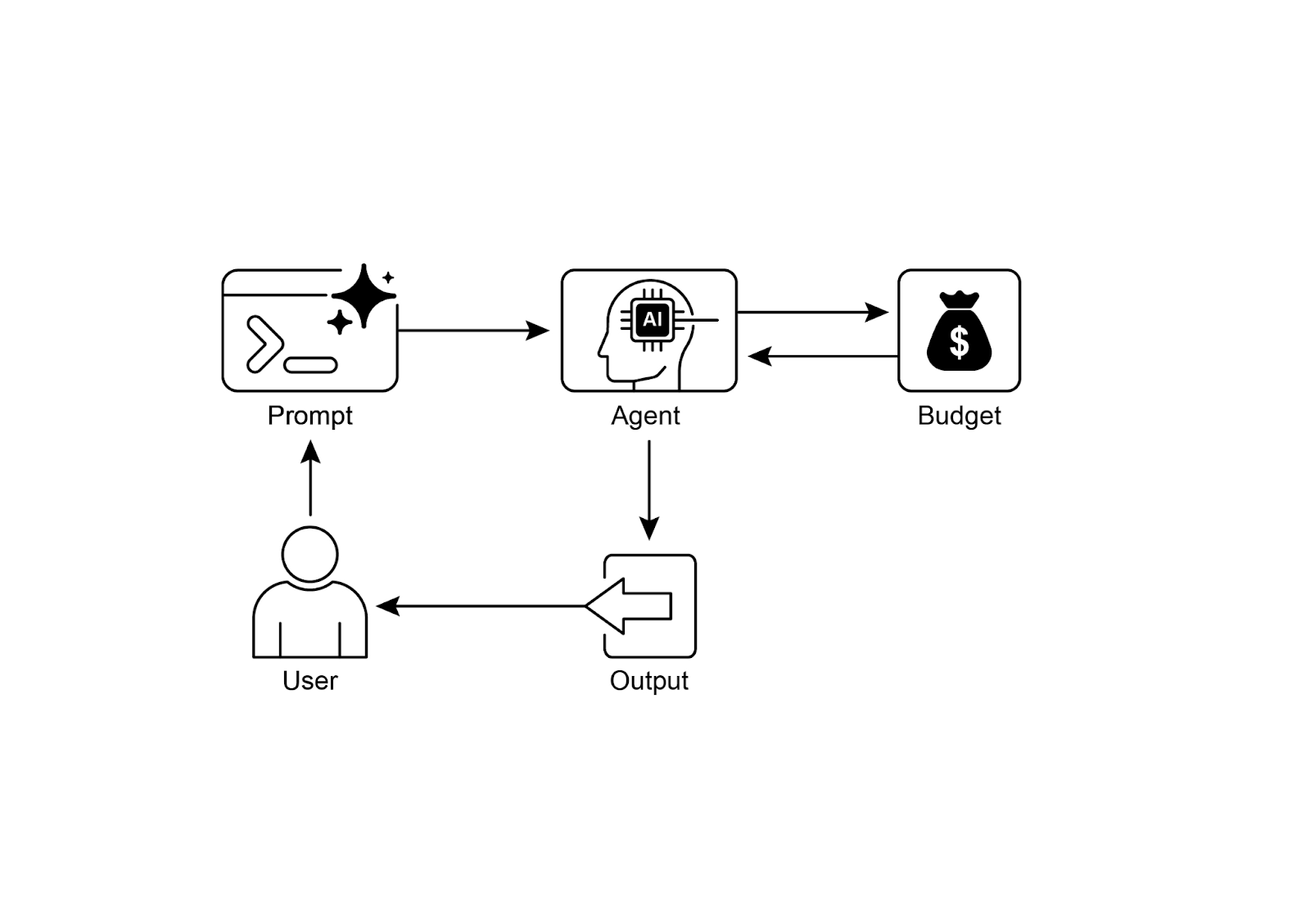
图 2:资源感知优化设计模式
Key Takeaways | 核心要点
- Resource-Aware Optimization is Essential: Intelligent agents can manage computational, temporal, and financial resources dynamically. Decisions regarding model usage and execution paths are made based on real-time constraints and objectives.
* 资源感知优化至关重要:具智能体特性的系统可以动态管理计算、时间和财务资源。关于模型使用和执行路径的决策基于实时约束和目标做出。
- Multi-Agent Architecture for Scalability: Google's ADK provides a multi-agent framework, enabling modular design. Different agents (answering, routing, critique) handle specific tasks.
* 可扩展的多智能体架构:Google 的 ADK 提供多智能体框架,支持模块化设计。不同的智能体(回答、路由、评论)处理特定任务。
- Dynamic, LLM-Driven Routing: A Router Agent directs queries to language models (Gemini Flash for simple, Gemini Pro for complex) based on query complexity and budget. This optimizes cost and performance.
* 动态的、由 LLM 驱动的路由:路由智能体根据查询复杂性和预算将查询引导到语言模型(简单查询使用 Gemini Flash,复杂查询使用 Gemini Pro)。这优化了成本和性能。
- Critique Agent Functionality: A dedicated Critique Agent provides feedback for self-correction, performance monitoring, and refining routing logic, enhancing system effectiveness.
* 评论智能体功能:专门的评论智能体为自我修正、性能监控和改进路由逻辑提供反馈,增强系统有效性。
- Optimization Through Feedback and Flexibility: Evaluation capabilities for critique and model integration flexibility contribute to adaptive and self-improving system behavior.
* 通过反馈和灵活性进行优化:评论的评估能力和模型集成灵活性有助于自适应和自我改进的系统行为。
- Additional Resource-Aware Optimizations: Other methods include Adaptive Tool Use & Selection, Contextual Pruning & Summarization, Proactive Resource Prediction, Cost-Sensitive Exploration in Multi-Agent Systems, Energy-Efficient Deployment, Parallelization & Distributed Computing Awareness, Learned Resource Allocation Policies, Graceful Degradation and Fallback Mechanisms, and Prioritization of Critical Tasks.
* 其他资源感知优化:其他方法包括自适应工具使用与选择、上下文修剪与摘要、主动资源预测、多智能体系统中的成本敏感探索、能源高效部署、并行化与分布式计算感知、学习型资源分配策略、优雅降级和后备机制,以及关键任务优先级排序。
Conclusions | 结论
Resource-aware optimization is essential for the development of intelligent agents, enabling efficient operation within real-world constraints. By managing computational, temporal, and financial resources, agents can achieve optimal performance and cost-effectiveness. Techniques such as dynamic model switching, adaptive tool use, and contextual pruning are crucial for attaining these efficiencies. Advanced strategies, including learned resource allocation policies and graceful degradation, enhance an agent's adaptability and resilience under varying conditions. Integrating these optimization principles into agent design is fundamental for building scalable, robust, and sustainable AI systems.
资源感知优化对于具智能体特性系统的开发至关重要,使其能够在现实世界约束下高效运行。通过管理计算、时间和财务资源,智能体可以实现最佳性能和成本效益。动态模型切换、自适应工具使用和上下文修剪等技术对于实现这些效率至关重要。包括学习型资源分配策略和优雅降级在内的高级策略增强了智能体在不同条件下的适应性和韧性。将这些优化原则整合到智能体设计中是构建可扩展、稳健和可持续的 AI 系统的基础。
References
参考文献
-
Google's Agent Development Kit (ADK): google.github.io/adk-docs
-
Gemini Flash 2.5 & Gemini 2.5 Pro: aistudio.google.com
-
OpenRouter: openrouter.ai/docs/quickstart
-
Google 智能体开发工具包(ADK):google.github.io/adk-docs
-
Gemini Flash 2.5 和 Gemini 2.5 Pro:aistudio.google.com
-
OpenRouter:openrouter.ai/docs/quickstart